
How AI Models "Learn" Things
Back at it again with the AI talk.

My previous post about machine learning language models has been my most viewed post yet. So I figured I could expand on it and talk about how these models get tuned since previously I wrote about their architecture and make up. I would highly recommend reading my first post, linked below, before continuing on with this one.

Let me reiterate a short disclaimer before I get into it. If the general population has about a kindergarten level of understanding when it comes to AI, that probably puts me at about a 4th grade level of understanding. But again, this is the internet after all, and I am happy to discuss topics where I am no expert in. And please, if any real AI engineers are reading this feel free to call my bull shit out in the comments below.
Alright, where were we? Magical black box with millions of input and output switches, and millions of tuning knobs, that’s right. I’m gonna call your attention to these “knobs” for this post. The question I will be attempting to answer is “how do these knobs get tuned during the training session of a machine learning model?” My comically reductive answer is as follows: computer scientists simply have the model guess answers over and over again, and each time, they tell the model if it is right or wrong. Now, something very important has to happen in between these guesses, the tuning knobs change ever so slightly, to produce a different result.
Let’s back up a little to before the training begins, and in some cases to before the model architecture is even decided. In order to train AI models, computer scientists need a butt load of data. I’m talking like enough to fill the Grand Canyon kind of data. In the field of machine learning these are called “data sets” and are typically broken into two parts, and sometimes more. But you need at least two independent data sets, one for training, and one for testing/validation.
These data sets look different depending on what kind of AI tool is being built. For something like ChatGPT the data set might look like a piece of text that is the prompt (a user's simulated input) and a corresponding piece of text that would represent the desired output for that given specific input. And there would be billions, or even trillions, of these prompt-response type data pairs. For a different type of machine learning architecture, let's say an image recognition tool, the data set would look like tons and tons of labeled images. Think reCAPTCHA style pictures of identifiable objects.

In general, the more data the better when it comes to training these AI tools, but also the quality of the data plays a big determining factor in the quality of the AI tool post-training. I mean think about it, if you trained ChatGPT solely on discourse from Twitter and r/politics, you’d create a monstrous vessel of vitriol and hate that would respond like the average Twitter/Reddit user. Notice that ChatGPT doesn’t do this (although it does seem to display a left-wing bias as of the writing of this post).
There are actually tons of free sources of machine learning training data sets out there. And when I was doing a little research for this post I came across this company that looks like they actually source and sell data sets for AI training. Kind of a nightmarish potential for a dystopian future if you ask me (or are we already there in terms of online user information farming *hint hint wink wink*).
So we have our data sets, and we have our machine learning model architecture, we’re finally ready to begin the training process. Here’s basically what happens: the computer scientist writes an autonomous training program that commands the machine learning model to sequentially go through the training data, and produce an output for each simulated input. Here’s probably something you might’ve never thought of: the very first output that ChatGPT ever produced during training was probably complete and utter gibberish. This has to do with the knobs I’ve been telling you about. When ChatGPT was birthed, its “knobs” were probably in a completely random and arbitrary configuration, thus its garbage output at the beginning. Throughout the training, when the autonomous training program tells ChatGPT that its output is incorrect, it kicks off a very complicated mathematical algorithm that tunes the knobs to produce a slightly better output next time. This process is called backpropagation, and it essentially decreases the error of the model’s output. It is absurdly complicated and I will forever be fascinated that there are real human beings out there that figured this shit out.
So basically, run this process over and over and over again with the training data, and you can cook up your very own ChatGPT. But I don’t think you need me to convince you that this is NOT a trivial task. For the sake of brevity I haven’t discussed machine learning overfitting or learning rate or model compression and its various techniques. I’d really be getting down into the weeds if I discussed those topics. But by all means if you have any questions about these leave them in the comments below and I will do my best to answer them.
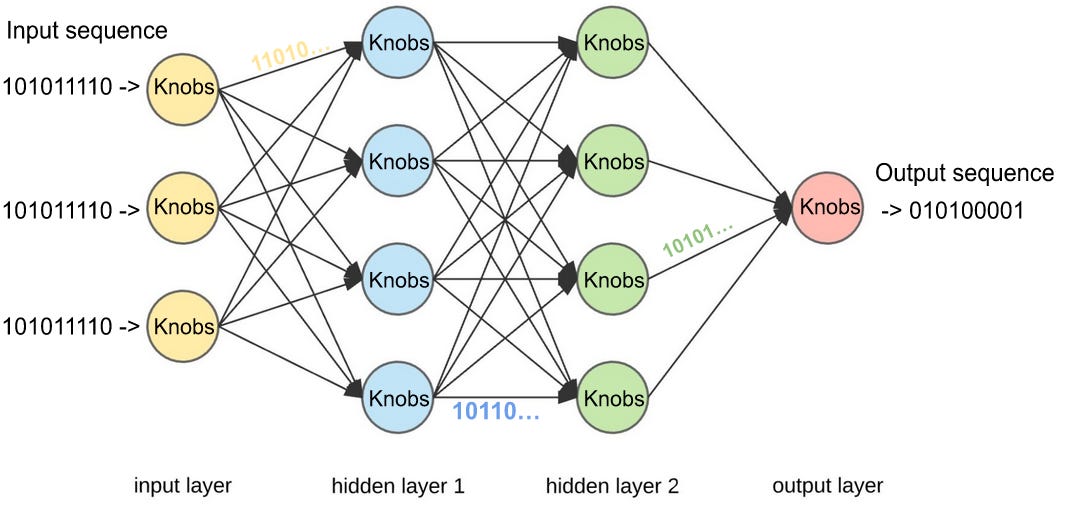
I hope I was able to teach you something about AI, and provide some “behind the curtain” insights into how these tools work. I will leave you with the diagram I have created below. It shows a neural network architecture at a lower level than I have described, but with the added labels and jargon that I have been using. A real AI engineer would call the circles a neuron or a node, I have been calling them knobs. The interconnections between the knobs are just more sequences of 1’s and 0’s, essentially one knob’s output is another knob’s input. These sequences have been transformed by applying the knob “weight” to them. My black box metaphor would seem to apply to each circle below, and not to the entire diagram. But actually it applies to both. The entire diagram can be viewed as one big black box that has lots of smaller black boxes interconnected on the inside. Boxception.
After reading my two posts about AI, what do you think about this technology? What do you think about my claim in the previous post that AI, as it presently stands, will not take over the world? Let me know in the coments below!